[#12] YOUSINSA, 이대로 괜찮은가?
개요
마지막 개선사항까지 포스팅을 완료했지만 그동안 면접, 포트폴리오 피드백을 다양하게 받으면서 알게 된 부분과 더불어서 이미 알고 있는 개선 필요 지점, 아쉬운 부분을 기록하기 위해 "이대로 괜찮은가" 편을 남기려고 합니다.

그리고 이렇게 기록된 사항을 바탕으로 다시 프로젝트를 이어서 진행하면서 개선해나가면서 최종적인 목표인 Version 4까지 달려가기 위한 증거로 남기고 싶었습니다.

YOUSINSA 프로젝트 테스트 시나리오의 한계
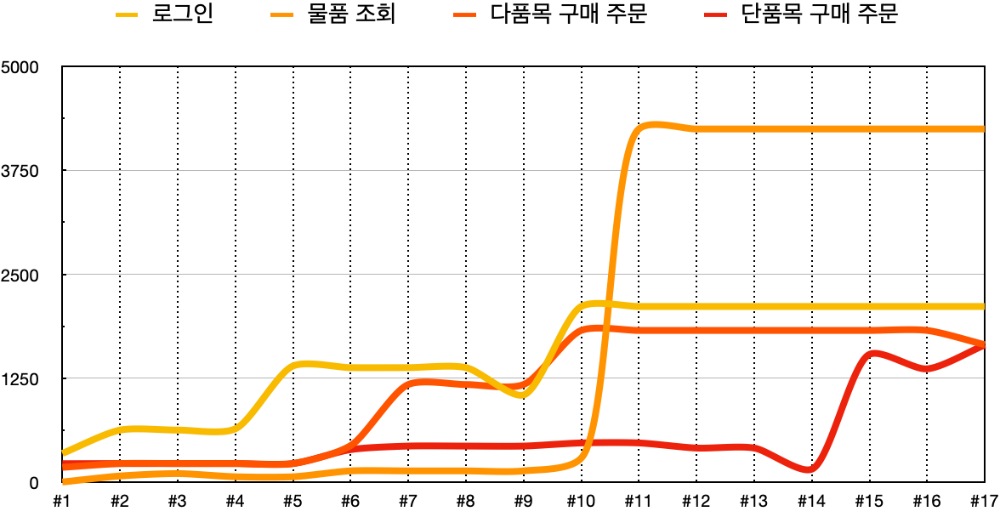
개선을 진행해서 목표한 동시 사용자 500명을 기준으로 각각의 API에 대해서 1250 TPS는 달성했습니다. 하지만 실서비스에서도 정상적으로 돌아갈 것이라 낙관할 수 있을까라는 의문이 들었습니다.
실서비스에서도 정상적으로 문제없이 돌아갈 것이라고 확신하게 되는 경우는 무엇이 있을지 고민했습니다.
실제 유저가 직접 사용하는 시나리오대로 테스트를 진행하면 오차가 줄어들지 않을까?
실제 유저는 어떻게 물품을 구매할지 고민해보면 로그인, 물품 조회, 상세 물품 조회, 물품 구매까지 일련의 프로세스로 간단하게 시나리오를 구성할 수 있을 것이라 예상됩니다. 주문 취소 혹은 상품 이미지와 관련된 기능 등은 기본 시나리오의 파생이라고 생각됩니다. 각각의 API는 목표 TPS를 달성했지만 더 큰 단위의 프로세스로 구성하게 된다면 목표 TPS를 달성할 수 있을지 고민해보면 주어진 테스트 결과로는 판단이 되지 않습니다.
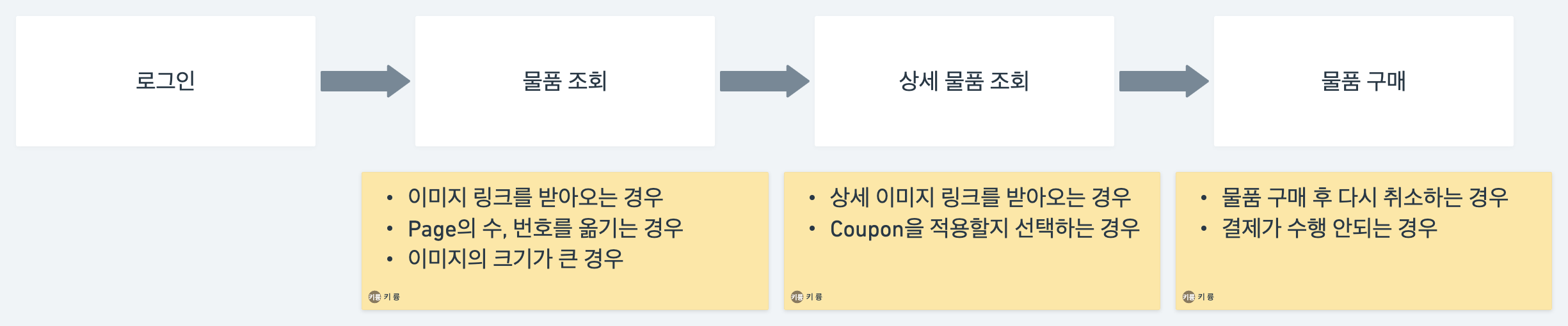
가상의 시나리오만 생각해보더라도 모든 API를 독립적으로 생각해 각 API가 목표에 다다르면 실서비스에서도 문제가 없을 것이라 예상했지만 Database, Redis와 같이 여러 관계가 있는 Component로부터의 다양한 상호 연관을 고려하면 더 정밀한 시나리오가 필요합니다.
만약 서비스가 더 성장하게 되어 MSA 환경으로 구축되어 있는 경우에도 각각의 Domain Application Server들이 격리되어 있지만 분산 트랜잭션, Message Queue, Server Component 간의 통신도 고려해야 되기 때문에 더더욱 사용자가 사용할 시나리오에 가깝게 테스트해야 하므로 현재 진행한 테스트의 경우 불완전합니다.
YOUSINSA 프로젝트 Architecture의 한계
SLA(Service Level Agreement)라는 용어는 서비스 수준 협약서라고 말하며 공급자와 사용자 간에 서비스에 대하여 측정지표, 목표 등에 대한 협약서를 지칭합니다. SLA에서 중요한 지표로는 다운 타임과 연관되어 99.9~99.999로 표시하는 서비스 수준 지표가 있습니다. 1년 중 어느 정도의 다운 타임을 보장할 것인지 나타냅니다. 특히 서비스의 서버는 1년 365일 무중단으로 운영되어야 고객들이 아무 문제없이 사용하여 수익률을 극대화하고 나아가 고객 경험도 개선할 수 있을 것입니다.
이를 위해 필요한 것은 바로 Availability(가용성)입니다. 현재 Infra Architecture는 다음과 같습니다.

과연 현재 Infra Architecture는 가용성이 높다고 말할 수 있을까요? NOPE
높은 가용성(HA)의 반대말이라고 생각되는 SPOF(Single Point of Failure)는 서비스에 치명적일 수 있습니다. 왜냐하면 하나의 지점이 문제가 있을 뿐인데 서비스 전체가 사용불가가 되기 때문입니다. 제가 생각하는 SPoF 지점은 4곳입니다.
- Load Balancer
- Redis
- Database
- Application Server Event Publisher(▲, 정확한 의미의 SPOF는 아님)
Load Balancer가 Fail 되면 Application Server로 Request가 전달이 안 될 것이기 때문에 서비스가 사용불가 상태가 됩니다. 다음으로 Redis는 Session 관리와 재고 관리를 하기 위해 사용하고 있습니다. 이 부분에서 Session Storage Redis가 Fail 된다면 로그인 관련 서비스들이 모두 사용할 수 없으므로 서비스를 이용할 수 없게 됩니다. 다음으로 재고 관련 Caching Redis가 Fail 된다면 재고의 정합성을 보장할 수 없는 상태로 운용되므로 정상적인 UX를 제공할 수 없습니다. 그리고 Database의 경우 모든 API에 관여하므로 Fail 되면 전체 서비스가 수행되지 않습니다.
마지막으로 만약 하나의 Application Server가 Fail 된다면 어떻게 될지 고민했습니다. 구매 주문이 접수되지 않은 경우 영향이 없을 것이나 구매 주문이 접수되어 진행되고 있는 중 Fail 된다면 해당 Event는 사라져 버릴 것입니다. 따라서 해당 Event를 발생시킨 구매 주문 요청은 재고 차감이 진행되지 않고 주문 상태는 진행 중 상태에 머물러 있으므로 단일 실패 지점으로 판단했습니다.
그래서 어떻게 SPoF를 방지할 것인가? 다중화가 필요, Primary-Secondary구조, Health-Check, Messaging-Queue
* 잘못된 부분이 있다면 피드백 감사합니다!
SPoF를 방지하기 위해서는 다중화, Health-Check, Message-Queue가 필요합니다.
Load Balancer는 최근 MSA 환경에서 SPoF 가능성, 서버 Resource 소모를 이유로 Service Discovery 방식으로 구성하거나 Docker 환경으로 구성되어 있다면 k8s, Docker Swarm과 같이 Container Orchestration을 사용, 혹은 Load Balancer의 설정을 통하여 Fail 환경에 대비할 수 있습니다.
* 더 정확히 표현한다면 단일 실패 지점(SPOF)에서 자유롭지 못한 Load Balancer를 제거하고 다른 방식의 접근도 고려해야합니다.
Redis 또한 Redis Clustering, Redis Sentinel을 통해 SPOF를 방지할 수 있습니다.
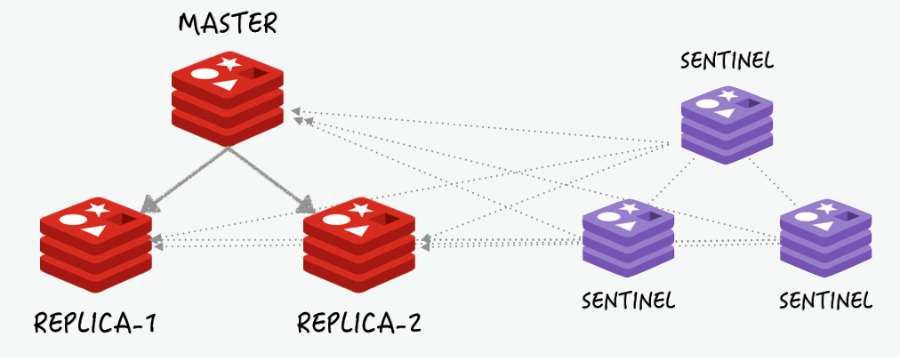
MySQL의 경우 Replication을 지원하여 Primary-Secondary 구조를 만들어 가용성을 높일 수 있습니다.
* Master - Slave란 용어와 혼용해서 사용하기도 합니다.
다음으로 Message-Queue의 경우 Event를 Publish 하는 부분을 담당하여 Event 혹은 Message가 유실되지 않도록 처리를 하여 잘못된 동작이 되지 않도록 할 수 있습니다.
* 이 부분에서는 의견이 틀릴 수 있다고 생각이 들어 개인적인 의견도 남깁니다.
Application Server가 Fail 되더라도 전체 시스템 자체가 Fail되는 것은 아니기 때문에 정확한 의미의 단일 실패지점으로 볼 수는 없습니다.

* 더 자세한 부분은 다른 포스팅을 통해 정리할 예정입니다.
YOUSINSA 프로젝트 설계의 한계
흔히 서버에서 발생하는 병목 지점이 될 확률이 높은 부분을 네트워크와 데이터 베이스를 지목합니다. 그렇다면 당연히 이런 병목 지점들이 발생하지 않도록 설계하는 것이 기본적인 원칙으로 생각됩니다. 하지만 이번 프로젝트를 설계를 시작할 때부터 개발을 진행할 때까지 지속적으로 문제가 되었던 부분은 Database 부분의 병목이었습니다.
직접 경험하지 않았지만 익히 알고 있는 문제점을 알고 있음에도 Database 중심적인 설계를 진행한 부분은 문제가 있다고 느껴집니다.
* 책 중 하나인 'Data Intensive Application Design'에서 말하는 데이터 중심 설계와는 관계없습니다.
이번 기회를 통해 직접 경험했으니 추후의 설계에서는 Database에 모든 상태를 담아 관리하는 것이 아니라 분산 환경을 고려하여 설계하고 모든 상태를 Database에 의존적이지 않게 설계할 필요성이 있습니다.
추가적으로 Database에서 병목이 발생하는 것은 Read/Write를 분리해서 생각할 수 있습니다. 개선 작업에서 특히 문제가 되는 부분은 Write(INSERT, UPDATE, DELETE)에서 실행되는 Lock에 의해서 발생했습니다. 따라서 이런 부분을 분리하여 Source-Replica 구조를 적용하여 Read는 Replica DB, Write는 Source DB로 쿼리 요청을 분배함으로써 성능적인 개선을 이룰 수 있을 것이라 예상합니다.
REF
https://aws.amazon.com/ko/message-queue/
메시지 대기열이란 무엇입니까?
최신 클라우드 아키텍처에서는 애플리케이션이 좀 더 쉽게 개발, 배포 및 유지 관리할 수 있는 더 작고 독립적인 빌딩 블록으로 결합 해제됩니다. 메시지 대기열은 이러한 분산 애플리케이션을
aws.amazon.com
'Project > YOUSINSA' 카테고리의 다른 글
| [#11] 재고 관리는 어떻게 해야될까? - 3. Eventually Consistency (0) | 2022.11.07 |
|---|---|
| [#11] 재고 관리는 어떻게 해야될까? - 2. Lua Script (0) | 2022.11.07 |
| [#11] 재고 관리는 어떻게 해야될까? - 1. Redis Transaction (0) | 2022.10.27 |
| [#10] 재고 관리 Integrity 문제 - 2 (0) | 2022.10.15 |
| [#10] 재고 관리 Integrity 문제 - 1 (0) | 2022.10.13 |