[#5] Scale-Up으로 검증
개요
#4를 통해서 Application Server의 Resource 부족으로 병목이 발생한다는 것을 알게 되었습니다. 만약 해당 가정이 참이라면 Application Server의 Resource를 Scale-Up 한다면 성능이 오르는 것은 자명합니다. Scale-Up을 진행한 이후에도 Pool Size에 대한 변화를 관찰하여 예상했던 가정을 재검증하는 작업을 거쳤습니다.
그동안 진행된 실험에서 JVM Heap Size로 인해 문제가 발생되지는 않았으므로 vCPU만 Scale-Up 하여 실험을 진행했습니다.
Scale-Up 예상 결과
먼저 사용 가능한 Resource들에 대해서 다시 한번 점검하고 실험 결과를 보여드리겠습니다.
- Heap Memory - 2GB
- CPU - 4vCPU
예상하는 실험 결과는 vCPU를 2vCPU에서 4vCPU로 Scale-Up 하게 되면 더 많은 Thread를 연산을 동시에 처리할 수 있으므로 TPS 성능이 증가하고 Database CPU 사용량도 증가할 것이며 이에 따라 최적 Database Connection Pool Size도 증가할 것이라고 예상했습니다.
TPS 비교
비교 그래프를 보면 2vCPU의 경우 Pool Size가 최소부터 최대 실험값까지 증가함에 따라 변동폭이 상대적으로 4vCPU에 비해 작은 것을 확인할 수 있습니다.
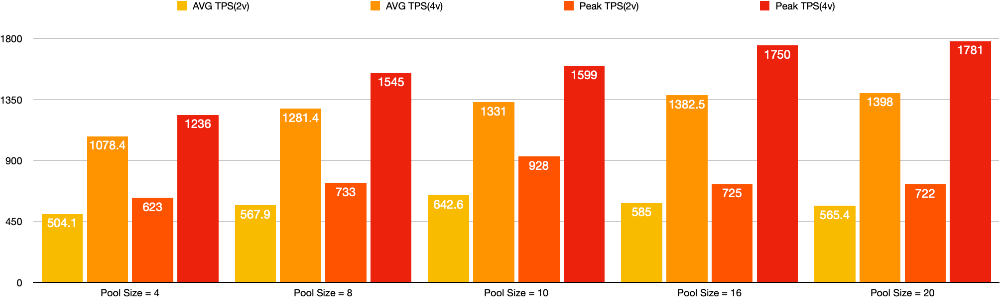
그리고 예상했던 바와 같이 적정 Connection Pool Size가 증가하는 것을 확인할 수 있었습니다. 너무 많은 비교 지표가 있어 구분이 힘듭니다. AVG TPS와 Peak TPS를 분리한 그래프도 첨부했습니다.
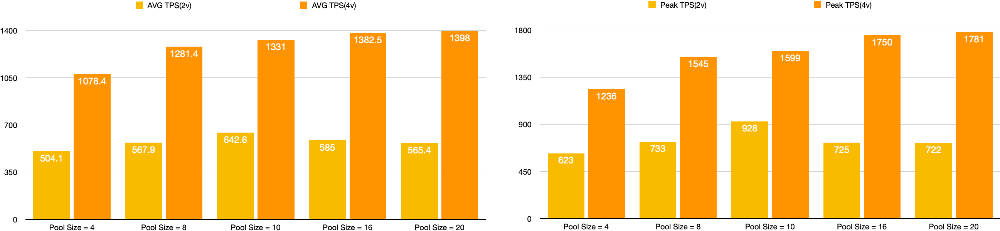
참이라고 가정했던 추론을 재검증해보니 실제로 Application Server의 vCPU의 부족으로 인해 병목이 발생한 것이 맞았습니다.
Resource 비교
여기서 Resource 비교를 통해 필요한 성능 개선 포인트들이 있나 살펴보았습니다.
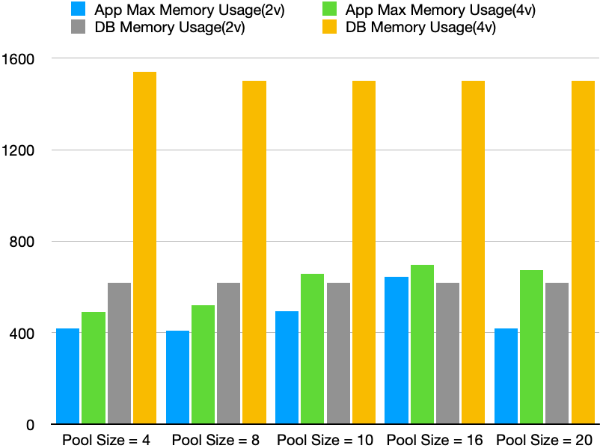
비교해보면 Application의 Memory 사용량은 크게 증가하지 않았지만 Database의 메모리 사용량은 크게 증가한 것을 볼 수 있었습니다.
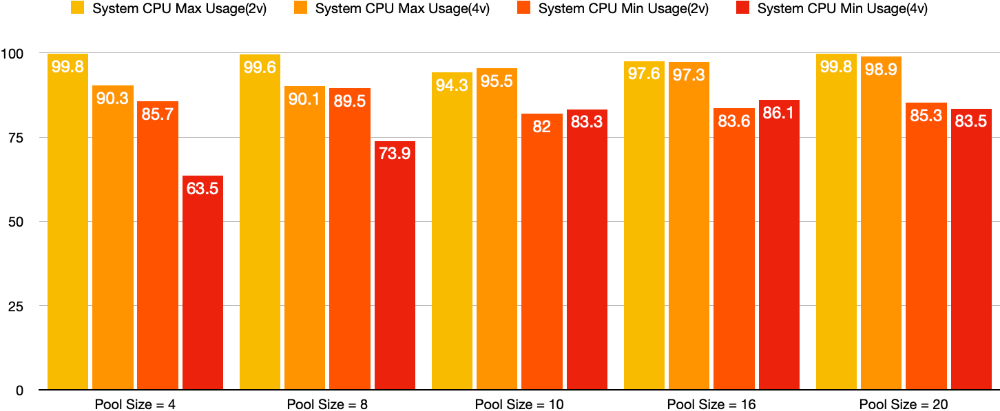
System CPU 사용량도 또한 비교해보면 2vCPU를 사용할 때에 비해 10% 이상 감소한 지표를 4개의 Pool Size를 가지고 있을 때 보여주고 Pool Size를 점점 증가시킬수록 4vCPU에서도 CPU 사용량이 증가하는 양상을 확인할 수 있었습니다.
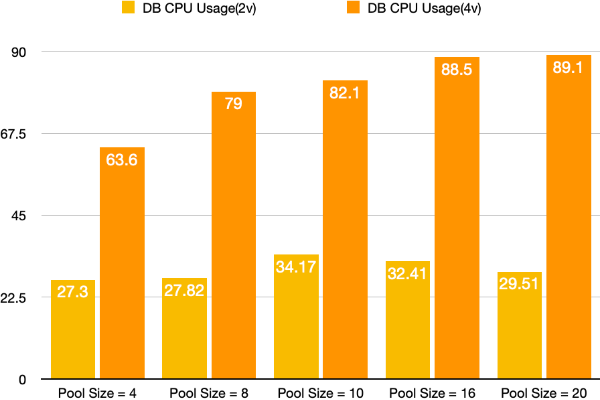
Database CPU 사용량 또한 증가했으며 4vCPU의 최적 Pool Size에서는 90% 정도의 사용량을 보입니다. 트래픽이 더 많아질수록 Database CPU 사용량이 더 증가하여 Database의 Resource 또한 부족하게 되는 가능성을 볼 수 있었습니다.
⛑ Database 사용량의 경우, Docker Stat을 통하여 통계를 산출했는데 이 부분에 오류가 있었습니다. Docker Stat은 하나의 Container가 사용할 수 있는 가용 자원에서의 사용량을 나타내는 명령어이므로 Prometheus, Grafana를 통해 확인한 지표와 차이가 나는 것을 확인했습니다. 추후 포스팅을 통해 Monitoring Tool의 도입과 어떤 오류를 범했는지 기록할 예정입니다.
Conclusion
Scale-Up을 통해 재검증하는 과정에서 3가지를 확인할 수 있었습니다.
- 성능 지표 상승
- ThreadPool의 존재를 재확인
- Optimum Pool Size 결정하기(feat. SSD)
성능 지표 상승
Database의 CPU 사용량이 증가한 것을 보았을 때 Connection을 더 많이 처리한다는 것을 알 수 있었습니다. 과정은 다음과 같습니다.
1. Application Server의 vCPU가 증가
2. 동시에 처리할 수 있는 Thread의 개수가 증가 → Connection을 처리할 수 있는 Thread가 많아짐
3. Database가 연산해야 하는 SQL이 많아짐 → Database CPU Usage 증가
4. Request → Response 사이클의 속도가 증가하고 이에 따라 TPS가 증가
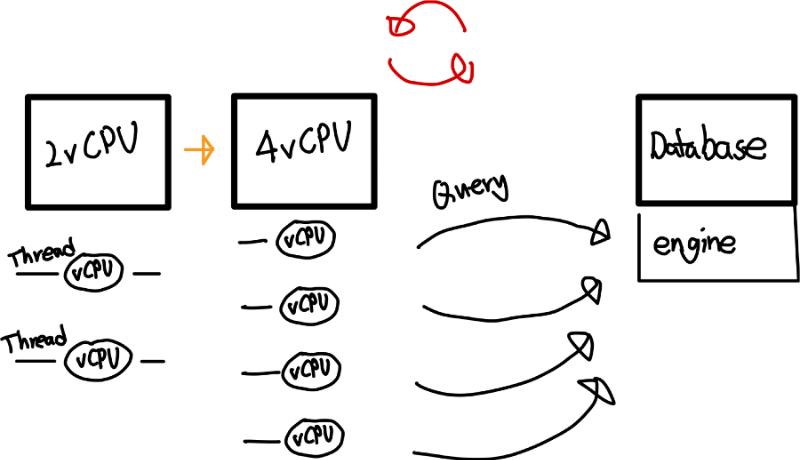
ThreadPool의 존재를 재확인
그동안 개념적으로 Thread Pool의 존재를 알고 있었으나 실제 실험에서 Thread Pool의 존재를 재확인할 수 있었습니다. 2vCPU에서 뿐만 아니라 4vCPU에서도 JVM의 최대로 생성된 Thread는 230개로 동일했습니다.
사용하는 Framework와 Library에서 ThreadPool을 사용하기 때문에 Thread 생성 개수가 제한됩니다. 그렇다면 더 적은 Resource에서 Thread를 더 많이 생성해 사용한다면 성능이 올라갈지 의문점이 생겼습니다. 추가적인 실험은 진행하지 않고 생각해보면 저의 답은 `아니오` 입니다.
이유는 HikariCP 공식문서에서 언급한 내용과 같은 맥락입니다. Thread가 많이 생성되더라도 현재 Resource 지표를 확인했을 때 CPU의 경우 충분히 사용하고 있으므로 더 잦은 Context Switching으로 성능이 저하될 것이라 예상됩니다.
* 하지만 결국 같은 원리로 적정한 ThreadPool의 갯수를 찾는다면 성능 향상 최적화 포인트가 될 수도 있습니다.
* 이런 최적화에 드는 시간과 성능 향상 폭을 고려하여 수행하면 좋다고 생각합니다.
Scale-Up을 통한 문제 해결의 한계점
가정했던 병목 지점의 원인을 파악하고 Scale-Up을 통해서 성능이 향상된 것도 확인했습니다. 하지만 ...
여전히 병목은 존재

StackTrace를 통해 확인해보면 Scale-Up 전보다 수행 시간이 이전보다 감소하는 것을 확인할 수 있지만 여전히 병목지점인 것을 확인할 수 있습니다. 그렇다면 여기서 더 Scale-Up을 진행하는 것이 맞을까에 대한 고민을 했습니다.
그 Spec이면 괜찮을까?
Service에 대한 성능 테스트 시작 시 트래픽 규모를 추정해서 1차 목표를 세웠었습니다.
| Active User | 500명 | 1000명 | 1500명 |
| Domestic Service(~400ms) | 1250 TPS | 2500 TPS | 3750 TPS |
| Global Service(~200ms) | 2500 TPS | 5000 TPS | 7500 TPS |
적어도 500명 이상의 국내 동시 사용자를 처리하기 위해서는 1250 TPS 이상을 유지해야 합니다. 그렇다면 1000명, 1500명을 위한 동시 사용자를 처리하기 위해서는 Scale-Up을 어느 정도까지 진행해야 할까요? 현재는 검증을 위해 로그인 API에 대해서만 테스트를 진행했지만 다른 API에서 목표 성능에 못 미친다면 또한 Scale-Up을 어느정도까지 진행해야 할까요?
가장 좋은 Spec의 서버로 Scale-Up 하면 모든 것이 해결될 수 있지만 이것 또한 한계가 존재합니다. 하드웨어의 기술이 더 발전되지 않으면, 사용하는 클라우드 서비스가 더 좋은 장비를 도입하지 않으면 트래픽을 감당할 수 있는 방법이 없습니다. 추가적으로 비용의 문제도 존재합니다. 만약 사용자 모두가 휴가를 떠나 이미 YOUSINSA에서 쇼핑을 끝내 접속을 하지 않는다면 이 좋은 서버를 놀게 해야 합니다.
이제는 Scale-Out을 해야 할 때
Scale-Up을 직접 진행하면서 성능 요구치에 따라 적절하게 Resource를 조절하는 유연한 구조를 갖기 위해서는 새로운 방식의 도입이 필요합니다.
바로 Scale-Out!
Scale-Out을 위한 작업을 곧바로 진행하고 싶지만 하나의 성능 개선 포인트를 적용하고 진행해 보겠습니다.
고민을 위한 여지
- 현재 서버 구성에서 Connection은 언제 획득되고 언제 반환될까?
- Docker Stat을 통해 Component의 사용량을 측정하는 것은 괜찮을까?
해당 프로젝트는 네이버 클라우드를 활용하여 진행했습니다.
'Project > YOUSINSA' 카테고리의 다른 글
| [#6] Connection 점유 시간 단축시키기 - HikariCP와 LazyConnectionDataSourceProxy 적용하기 (2) | 2022.10.01 |
|---|---|
| [#6] Connection 점유 시간 단축시키기 - AutoCommit 설정 (0) | 2022.09.27 |
| [#3 ~ #4] Database Connection PoolSize 최적화 (0) | 2022.09.26 |
| [#2] 쿼리 문제 최적화 (0) | 2022.09.22 |
| [#1] 서버 인프라 개선하기 - 구매주문 API 테스트 (0) | 2022.09.08 |